回顾
上一篇训练神经网络是用的是批梯度下降,容易陷入鞍点中。Pytorch 提供了一个数据集加载工具,使得我们可以方便地用小批量随机梯度下降来训练网络。其包含两个部分:
- Dataset: 用于构造数据集(支持索引)
- DataLoader: 每次拿出一个Mini-Batch用于训练更新
Epoch,Batch-Size,Iterations 概念释义
- Epoch: 表示一个训练周期,所有样本都进行一次前馈、反馈计算
- Batch-Size: 表示一个Mini-Batch包含的样本数量,即每次训练(一次更新)时用到的样本数量
- Iterations: 全部样本被划分的Mini-Batch的数量,如1000个样本,Batch-Size=100,那么Iteration=10
1 | # 训练循环 |
DataLoader
1 | torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None) |
参数释义:
- dataset (Dataset) – dataset from which to load the data.
- batch_size (int, optional) – how many samples per batch to load (default: 1).
- shuffle (bool, optional) – set to True to have the data reshuffled at every epoch (default: False).
- sampler (Sampler, optional) – defines the strategy to draw samples from the dataset. If specified, shuffle must be False.
- batch_sampler (Sampler, optional) – like sampler, but returns a batch of indices at a time. Mutually exclusive with batch_size, shuffle, sampler, and drop_last.
- num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
- collate_fn (callable, optional) – merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.
- pin_memory (bool, optional) – If True, the data loader will copy Tensors into CUDA pinned memory before returning them. If your data elements are a custom type, or your collate_fn returns a batch that is a custom type, see the example below.
- drop_last (bool, optional) – set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False)
- timeout (numeric, optional) – if positive, the timeout value for collecting a batch from workers. Should always be non-negative. (default: 0)
- worker_init_fn (callable, optional) – If not None, this will be called on each worker subprocess with the worker id (an int in [0, num_workers - 1]) as input, after seeding and before data loading. (default: None)
假设batch_dize=2,shuffle=True,经DataLoader过程如下:
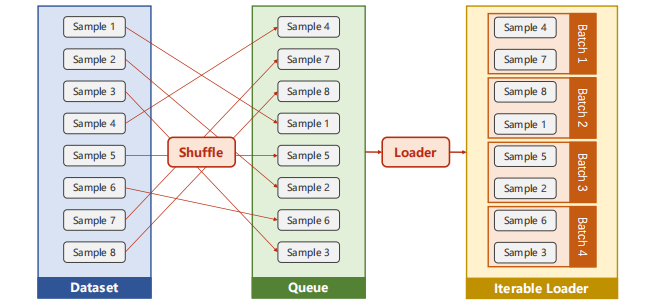
从左至右先打乱样本顺序最终得到一个可迭代的Loader,每次迭代将(yield)产生一个Mini-Batch用于训练网络。
Dataset
Dataset 是一个抽象类,无法被实例化。只能被其子类继承,再实例化。因此,若要实例化Dataset我们必须自己写一个类来继承自它。其结构大致为:
1 | from torch.utils.data import Dataset # Dataset 是一个抽象类,不能实例化 |
实例化数据集对象:
1 | dataset = DiabetesDataset(filepath) |
糖尿病数据集
加载数据集:
1 | import torch |
训练:
1 | for epoch in range(100): |
Pytorchvision 库内置的数据集
- MNIST
- Fashion-MNIST
- EMNIST
- COCO
- LSUN
- ImageFolder
- DatasetFolder
- Imagenet-12
- CIFAR
- STL10
- PhotoTour
这些数据集都继承与 torch.utils.data.Dataset,都具有getitem和len函数的实现,可以直接用torch.utils.data.DataLoader进行加载。
引入方式
1 |
|