一文读懂并查集
假设你现在置身于一个鸡尾酒会中,任何人都不能通过直接搭讪来获得陌生漂亮妹子的微信号。于是你委托你的朋友帮忙,你的朋友委托他的朋友。。。直到找到一位与漂亮妹子认识的人拿到了微信号。因此,你通过这些中间朋友与妹子取得了联系,成功进入了她的社交圈。当然,你可以通过她认识跟多的漂亮妹子,走上人生巅峰。
但是设想一下这样一个悲剧,那位漂亮妹子刚来到地球,她与地球上所有的人类都没有联系,那么你就无法通过中间人去认识她。你与她属于两个互不相交的社交圈。
现在,不妨稍稍抽象一下,将酒会比作一个个人(元素)组成的集合,而集合中人与人间的关系比作元素与元素间的关系。那么,想要探讨两个人(元素)间是否能取得联系,只要看两者是否属于同一社交圈中,即是否有联系。
而 并查集 的作用就是依赖这些元素两两间的联系来将这些元素区分为各个不相交的集合(社交圈),这样就可以判断两个元素是否直接或间接有联系。
举个栗子:
现在我们假设酒会中有 6 个编号从 0 到 5 的人,并且他们两两之间的联系{(0,1),(1,2),(1,3),(4,5)}; 因此他们之间的关系网络如下图:
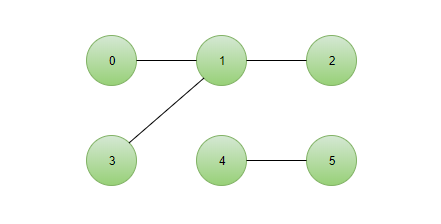
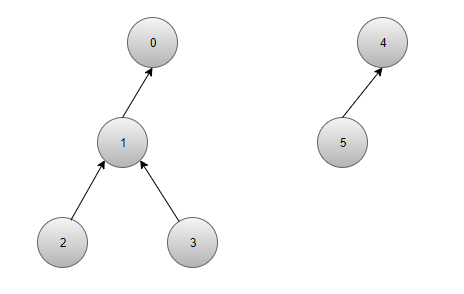
由于图中的边都是双向的,为了编程方便,不妨为各个连通分量分别指定一个根结点成为一棵棵树。如此一来要想判断两个结点之间是否有联系只需判断他们是否有相同的根节点即可(属于同一棵树)。由此关系网络转化为一个森林,森林中的每一棵树都是一个集合:
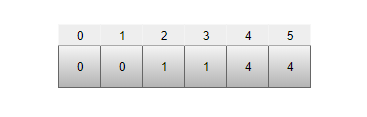
为了方便找出每一个结点的父结点,我们采用 树的双亲存储结构 来存储森林,如下图(ParentOf 数组):
到此为止,已经了解了并查集是什么。接下来就是并查集的实现了。
并查集的实现
求节点所在集合的根节点:
1 | int get_root(int x,vector<int>& parent) |
并操作(根据两俩关系建立森林(parent数组)):
1 | int union_verts(int x, int y,vector<int>& parent,vector<int>& rank) |
查操作:
1 | bool quary(int x, int y, vector<int>& parent) |
缺陷及其优化
上述算法完全可以实现并查集,但是由于上述算法的并操作只是简单第将两棵树合并而不考虑两树的高度,这在某些极端情况下生成的树的高度会非常大(如下图)。而并查集操作的时间复杂度取决于树高,因此该算法的时间复杂度将会从 $O(\log_{2}{N})$ 退化成为 $O(N)$。
因此,在合并两棵树的操作时我们要判断是将哪一棵树的根节点作为新树的根节点才能保证新树的高度尽可能小。举例如下图:
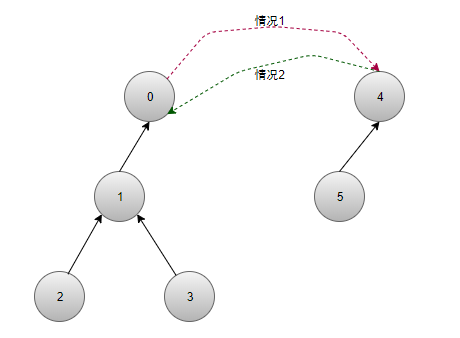
显然,存在两种情况:
情况 1:新树树高为 4
情况 2:新树树高为 3
毫无疑问,应该按情况 2 来合并。
在并操作中作相应修改(路径压缩):
总结所有的情况:
- 两树等高:随便合并
- 两树不等高:将较矮的树并到较高的树中
因此,我们需要记录以某节点为根的子树的高度,存储在rank数组中。rank[i] 表示以 i 节点为根的子树的高度。
1 | int union_verts(int x, int y,vector<int>& parent,vector<int>& rank) |
这样一来,就有效避免了树的狂长。
实验:
1 | int main() |
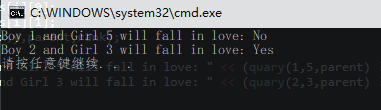
结果: