题目描述:
外国友人仿照中国字谜设计了一个英文版猜字谜小游戏,请你来猜猜看吧。
字谜的迷面 puzzle 按字符串形式给出,如果一个单词 word 符合下面两个条件,那么它就可以算作谜底:
- 单词 word 中包含谜面 puzzle 的第一个字母。
- 单词 word 中的每一个字母都可以在谜面 puzzle 中找到。
例如,如果字谜的谜面是 “abcdefg”,那么可以作为谜底的单词有 “faced”, “cabbage”, 和 “baggage”;而 “beefed”(不含字母 “a”)以及 “based”(其中的 “s” 没有出现在谜面中)。
返回一个答案数组 answer,数组中的每个元素 answer[i] 是在给出的单词列表 words 中可以作为字谜迷面 puzzles[i] 所对应的谜底的单词数目。
示例:提示:1
2
3
4
5
6
7
8
9
10
11输入:
words = ["aaaa","asas","able","ability","actt","actor","access"],
puzzles = ["aboveyz","abrodyz","abslute","absoryz","actresz","gaswxyz"]
输出:[1,1,3,2,4,0]
解释:
1 个单词可以作为 "aboveyz" 的谜底 : "aaaa"
<!-- more -->1 个单词可以作为 "abrodyz" 的谜底 : "aaaa"
3 个单词可以作为 "abslute" 的谜底 : "aaaa", "asas", "able"
2 个单词可以作为 "absoryz" 的谜底 : "aaaa", "asas"
4 个单词可以作为 "actresz" 的谜底 : "aaaa", "asas", "actt", "access"
没有单词可以作为 "gaswxyz" 的谜底,因为列表中的单词都不含字母 'g'。- 1 <= words.length <= 10^5
- 4 <= words[i].length <= 50
- 1 <= puzzles.length <= 10^4
- puzzles[i].length == 7
- words[i][j], puzzles[i][j] 都是小写英文字母。
- 每个 puzzles[i] 所包含的字符都不重复。
题解:
法一:暴力枚举判断(超时)
这个算法很直观,无非就是遍历枚举每一个谜面,判断words中能作为它的谜底的word的个数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48vector<int> findNumOfVaildWords(vector<string>& words, vector<string>& puzzles)
{
vector<int> res;
for(auto i : puzzles)
{
int charcounter[26] = {0};
for(auto j : i)
{
charcounter[j-'a']++;
}
int ans = 0;
for(auto k : words)
{
bool flag = true;
unordered_set<char> chset;
for(auto m : k)
{
chset.insert(m);
if(chset.size()>7)
{
flag = false;
break;
}
}
if(flag)
{
if(chset.find(i[0])==chset.end())
continue;
else
{
auto iter = chset.begin();
bool flags = true;
for(;iter != chset.end();iter++)
{
if(charcounter[(*iter)-'a'] <= 0)
{
flags = false;
break;
}
}
if(flags) ans++;
}
}
}
res.push_back(ans);
}
return res;
}
法二:暴力枚举+位运算(超时)
已知int行为32位,而小写字母有26个,因此用一个int型的整数就能够表示字符串中是否出现某字符:

上图就可以表示字符串“anwvw”
因此思路就是沿用上面的暴力枚举方法,只不过将字符串查询比较转化为整数的比较。
1 | vector<int> findNumOfVaildWords_BTL(vector<string>& words, vector<string>& puzzles) |
这个算法虽然比第一个好点但是当面对更大规模的测试样例时还是会超时。
法三:位运算+哈希
分析题设,根据第一个成为谜底的条件就是word中必须包含puzzle中的第一个字符,因此可以建立26个字符与包含该字符的word的整数表示所组成的数组的映射关系:
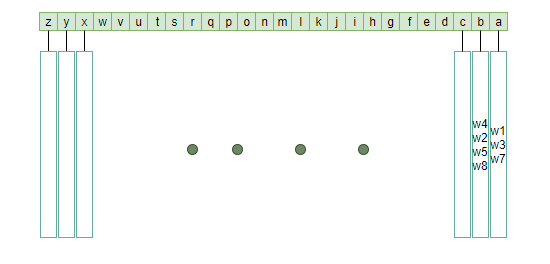
如此一来,我们就只需判断包含puzzle首字符的word是否是谜底就可以了,减少了很多无用重复的比较。
再者,不难发现若某一个word是puzzle的谜底那么其包含的字符种类肯定小于等于puzzle所包含的字符种类,这体现在整数化的字符串中就是:intOfWord的二进制值中 1 的位数肯定少于或等于intOfPuzzle中 1 的位数,并且intOfWord中 1 出现的位必将也是intOfPuzzle中 1 出现的位。因此对intOfWord和intOfPuzzle取余就会得到它们共同拥有的字符的字符串的整数表示,若该结果等与intOfWord就表明此时的word就是谜底。
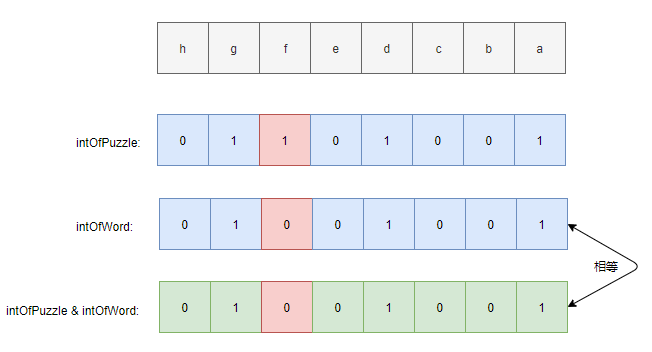
最终算法如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32vector<int> findNumOfValidWords(vector<string>& words, vector<string>& puzzles) {
//v用来保存含有'a'+i字母的word的二进制数
vector<int> hashV[26];
for (auto& i : words) {
unordered_set<char> s(i.begin(), i.end());
int tmp = 0;
//生成一个谜底word的二进制数
for (int ii = 0; ii < 26; ii++)
if (s.count('a' + ii))
tmp = tmp^(1 << ii);
//
for (char j : s)
hashV[j - 'a'].push_back(tmp);
}
//结果数组ans
vector<int> ans;
//
for (auto& i : puzzles) {
int at = i[0] - 'a';//记录首字母
unordered_set<char> s(i.begin(), i.end());
int tmp = 0;
//生成一个谜面的二进制数
for (int ii = 0; ii < 26; ii++)
if (s.count('a' + ii))
tmp ^= 1 << ii;
ans.push_back(0);
for (int j : hashV[at]) //hashV[at]中保存的是包含puzzle首字母的word的二进制数
if ((j & tmp) == j) //j & tmp 会得到它们共同拥有的字符的二进制数,
ans.back()++; //若其值与(j)不相等则表示word中含有puzzle中不含的字符
}
return ans;
}
运行测试:
1 | int main() |